Simplify Data Transformations in Snowflake
Build, operate and monitor data transformation jobs for the Snowflake Data Cloud.
Native Data Transformations for the Data Cloud
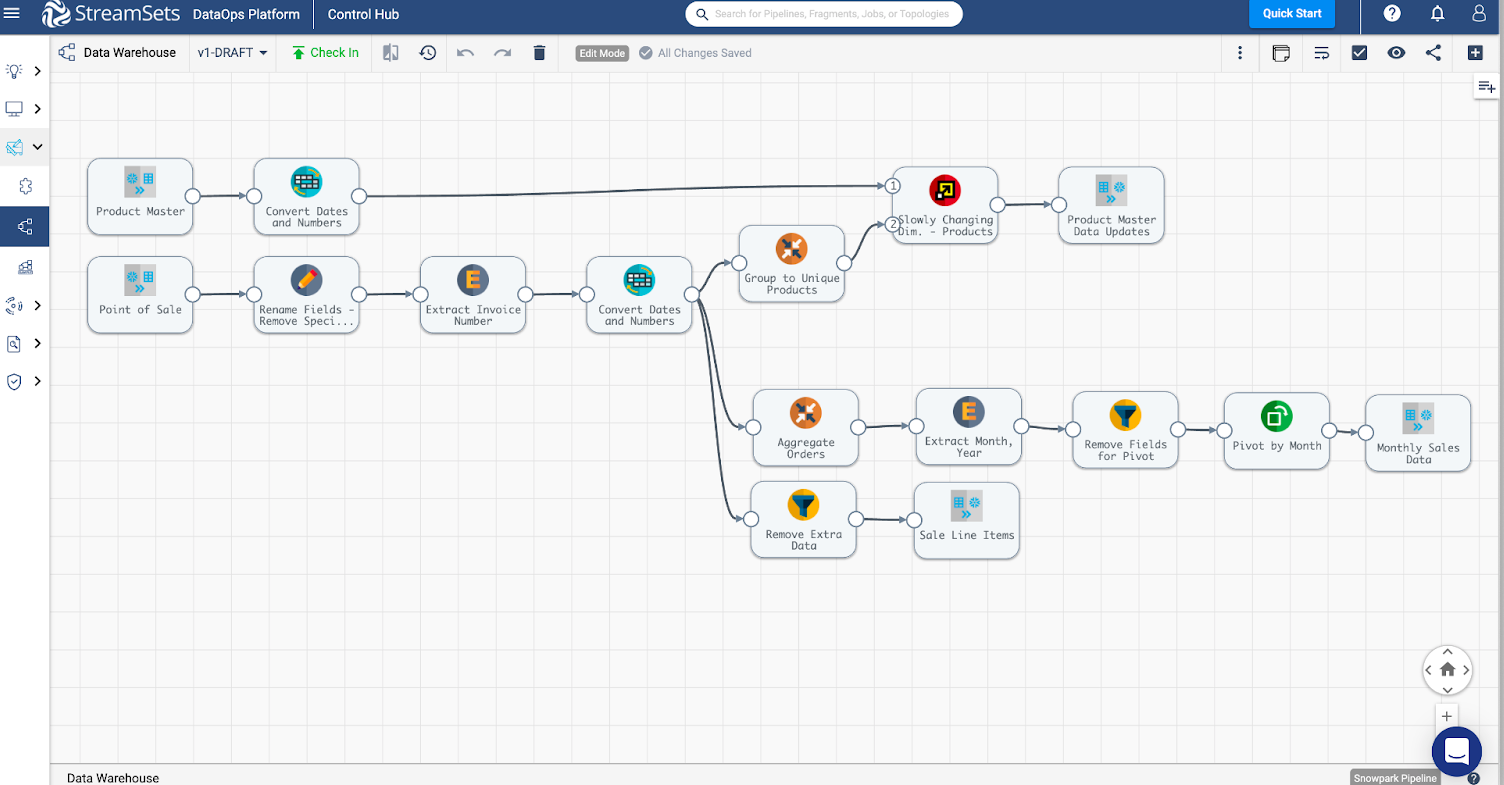
With StreamSets Transformer for Snowflake, data practitioners can take their data transformation to the next level. Users are no longer limited to SQL and can adopt a no-code approach with an intuitive design canvas to make data transformation and cleansing easy. StreamSets Transformer for Snowflake streamlines your data transformation process, helping you get more value from your Data Cloud than ever before.
StreamSets Transformer for Snowflake is designed for any data practitioner as well as less technical users to build ELT and data transformation pipelines that execute natively on Snowflake.
Built for Snowflake
StreamSets is a proud Snowflake Premier Technology Partner that maximizes your Snowflake investment.
Accelerate Your Snowflake Journey With StreamSets
Learn How To Get Started

Start a Free Trial
Start a Free Trial and see how to get even more value out of Snowflake Data Cloud.


Accelerate Your Data Cloud Development
Empower Self-service and Collaboration
Transformer for Snowflake enables users to effortlessly share and reuse transformation jobs, schedule workflows, and collaborate effectively across teams. It is designed to be intuitive and familiar, seamlessly extending the Snowflake experience. By expertly handling the intricacies of SQL syntax and functions, we save users valuable time in onboarding new team members, allowing them to quickly realize the immense value of Snowflake.
In-Place Transformations
Modify and manipulate your data directly within Snowflake, without the need to extract, transform, and load it elsewhere. This eliminates the cost and complexity associated with moving data in and out of Snowflake. By enabling seamless transformations within Snowflake’s data cloud, StreamSets Transformer empowers you to streamline data processing pipelines and accelerate insights while maximizing efficiency.




