Data Integration for Hybrid & Multi-Cloud Environments
Keep pace with need-it-now data demands, faster and with fewer resources.
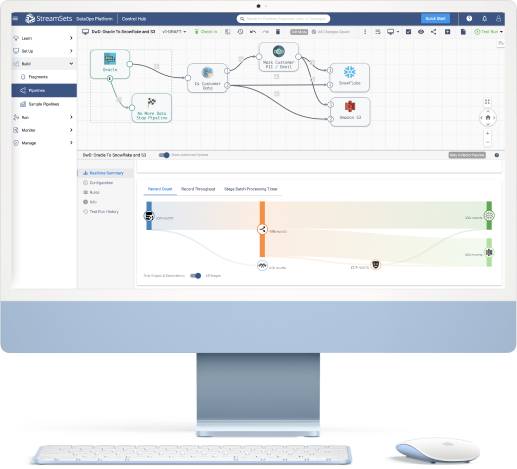


Leading Enterprises Run Millions of Data Pipelines with StreamSets
Accelerate Your Snowflake Journey With StreamSets
Learn How To Get Started

Start a Free Trial
Start a Free Trial and see how to get even more value out of Snowflake Data Cloud.
Data Professionals Around the World Have Spoken
Eliminate Data Integration Friction
In a highly competitive environment, making smarter decisions faster dramatically impacts business outcomes. All it takes is data, integrated across your enterprise. Just one problem; 68% of data leaders say data integration friction prevents them from delivering data at the speed of business requests.
The right data integration platform eliminates friction so you can quickly support diverse LOBs — even when data engineering resources are scarce.




Insulate Your Data Pipelines From Unexpected Shifts
Using cloud providers’ native data integration tools or enforcing centralized systems with top-down controls results in overly complex and brittle architectures that drive up costs and impede agility.
With StreamSets dynamic pipelines, you can introduce change without worrying about breakage.
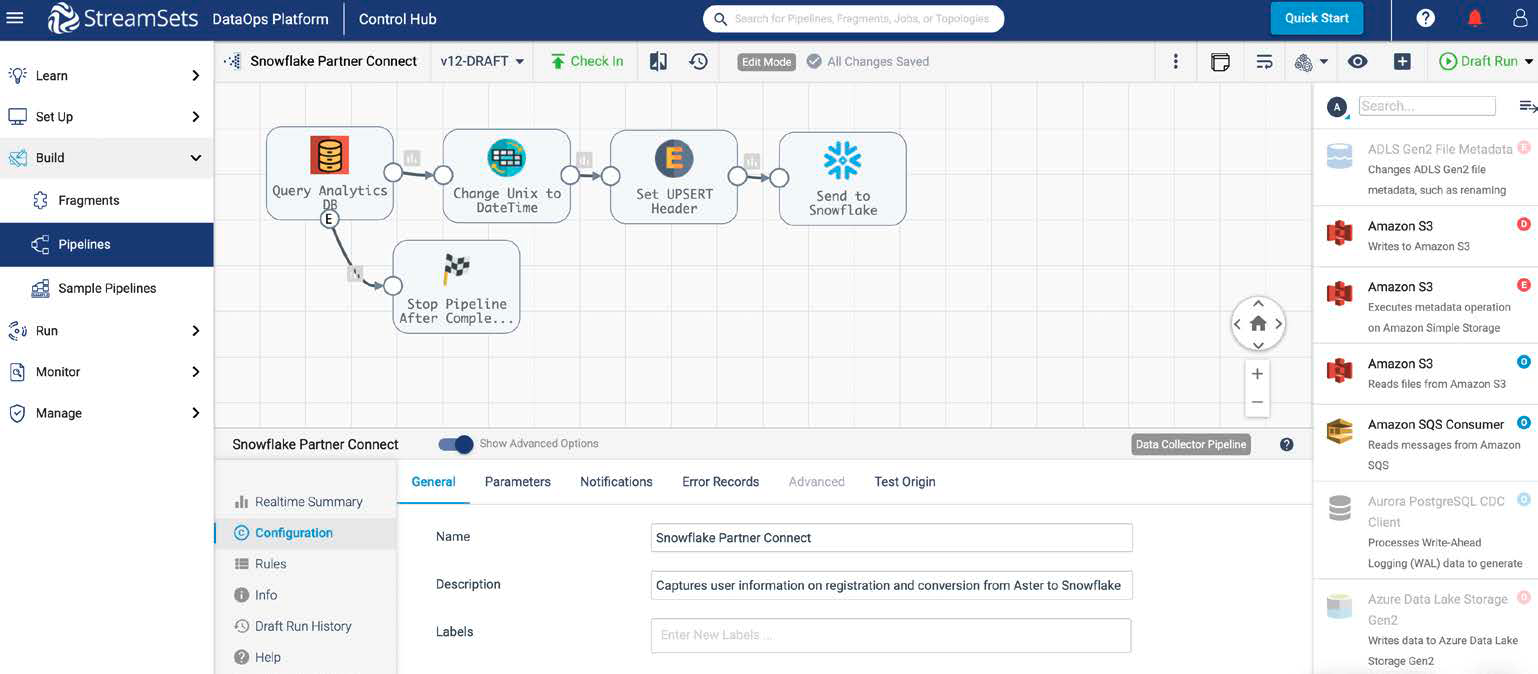
Easily Capture, Reuse, and Refine Business Logic
The skill set to build complex business logic is scarce, and when talent leaves, their knowledge walks out the door with them. When changes are inevitably needed your pipelines then break, disrupting data flows and the business operations that rely on them.
With reusable pipeline fragments, you can encapsulate expert knowledge in portable, shareable elements that stay up-to-date, no matter where they are used
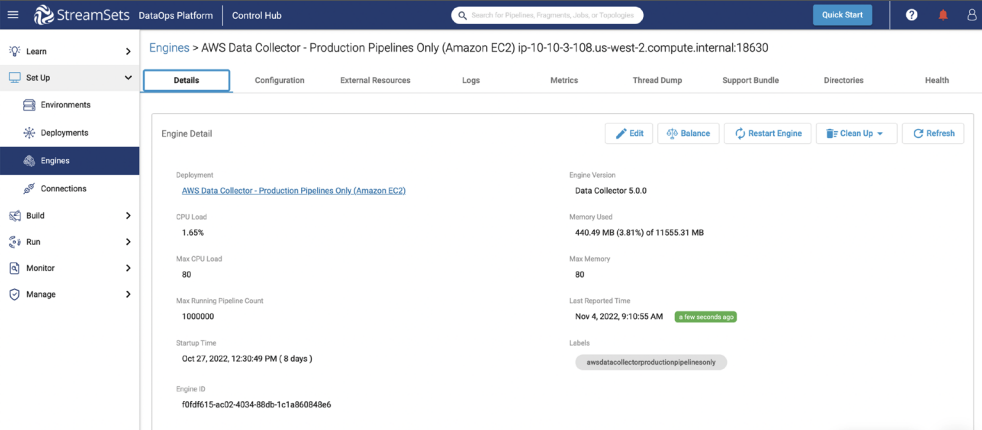
Flexibly Run Your Data Pipelines on Any Cloud, Hybrid or On-Premises Environment
Technology today moves fast, and your infrastructure and platform choices need to evolve accordingly. But too often, the high barriers of making those shifts keep you operating in a sub-optimal environment.
With infrastructure change management, you can flexibly run your data pipelines in any cloud provider or on-premises environment. Remove the constraints of past decisions and make the technology decisions that are best for your business right now.
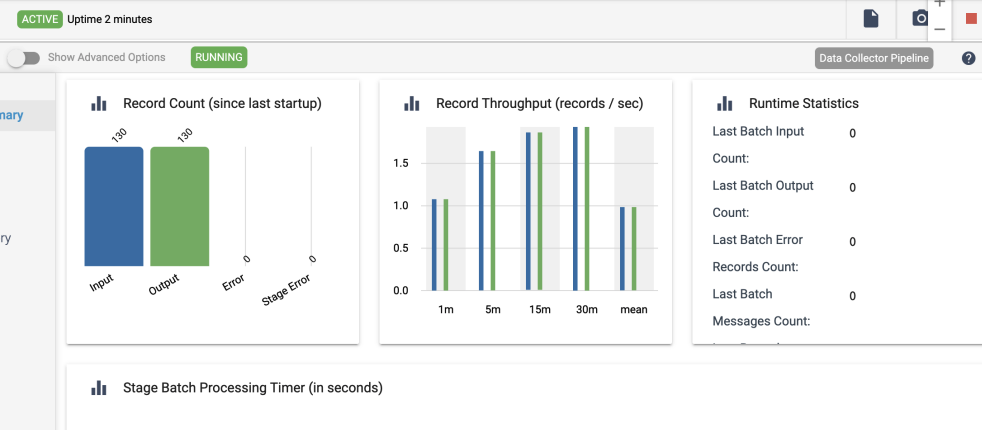
Democratizing Data Access to Drive Business Results


State of Ohio: Overnight COVID-19 Data Dashboard
“With StreamSets we can easily take and use any file format [for the COVID pipeline].”
Sagar Mangam, Avaap for State of Ohio

GSK: Advancing New Drug Discovery
“With StreamSets, we were able to deploy a million pipelines for thousands of data sources.”
Mark Ramsey, SVP of R&D Data, GSK

Humana: Digital Transformation in Healthcare
“StreamSets technologies and DataOps practices allow us to deliver the business outcomes that we’re focused on and make an impact on the people we serve every day.”
Anne-Britton Arnette, VP, Information Management and Analytics, Humana

RingCentral: Quality of Service and Fraud Protection
“RingCentral can now address quality of call service in real-time allowing us to make immediate adjustments to the network and carriers.”
Michael Becker, Senior Director of Big Data, RingCentral
Data Engineer’s Handbook: 4 Cloud Design Patterns
Ready to Get Started?
We’re here to help you start building pipelines or see the platform in action.